
[Review] 『그로킹 동시성』 : 데이터엔지니어 관점에서 동시성 이해하기
데이터 엔지니어의 관점에서 보는 『그로킹 동시성』

1. 동시성이 중요한 이유
현대의 소프트웨어 개발, 특히 데이터 엔지니어링에서 동시성과 병렬성은 필수적인 개념이다. 데이터 파이프라인이 대량의 데이터를 빠르고 안정적으로 처리하려면 여러 작업을 동시에 수행해야 하고 이를 위해 적절한 동시성 모델을 선택하는 것이 중요하다.
『그로킹 동시성』은 동시성과 비동기성의 개념을 깊이 있게 다루면서도 직관적이고 쉽게 이해할 수 있는 방식으로 설명한다. 데이터 엔지니어링의 맥락에서 보면 이 책은 대규모 데이터 처리 시스템을 구축할 때 반드시 이해해야 하는 개념들을 다루며 실무에서도 주로 사용하는 Spark, Flink, Kafka, Airflow 등 분산, 병렬 도구를 효과적으로 활용하는 데 도움이 된다.
나중에 알게 되었는데 이 책의 저자인 키릴 보브로프(Kirill Bobrov)는 데이터 엔지니어로 활동하며 여러 고부하 애플리케이션의 설계와 개발을 담당했다. 그만큼 동시성과 데이터 엔지니어링은 떼려야 뗄 수 없는 밀접한 관계를 가지고 있다.
2. 『그로킹 동시성』 핵심 개념
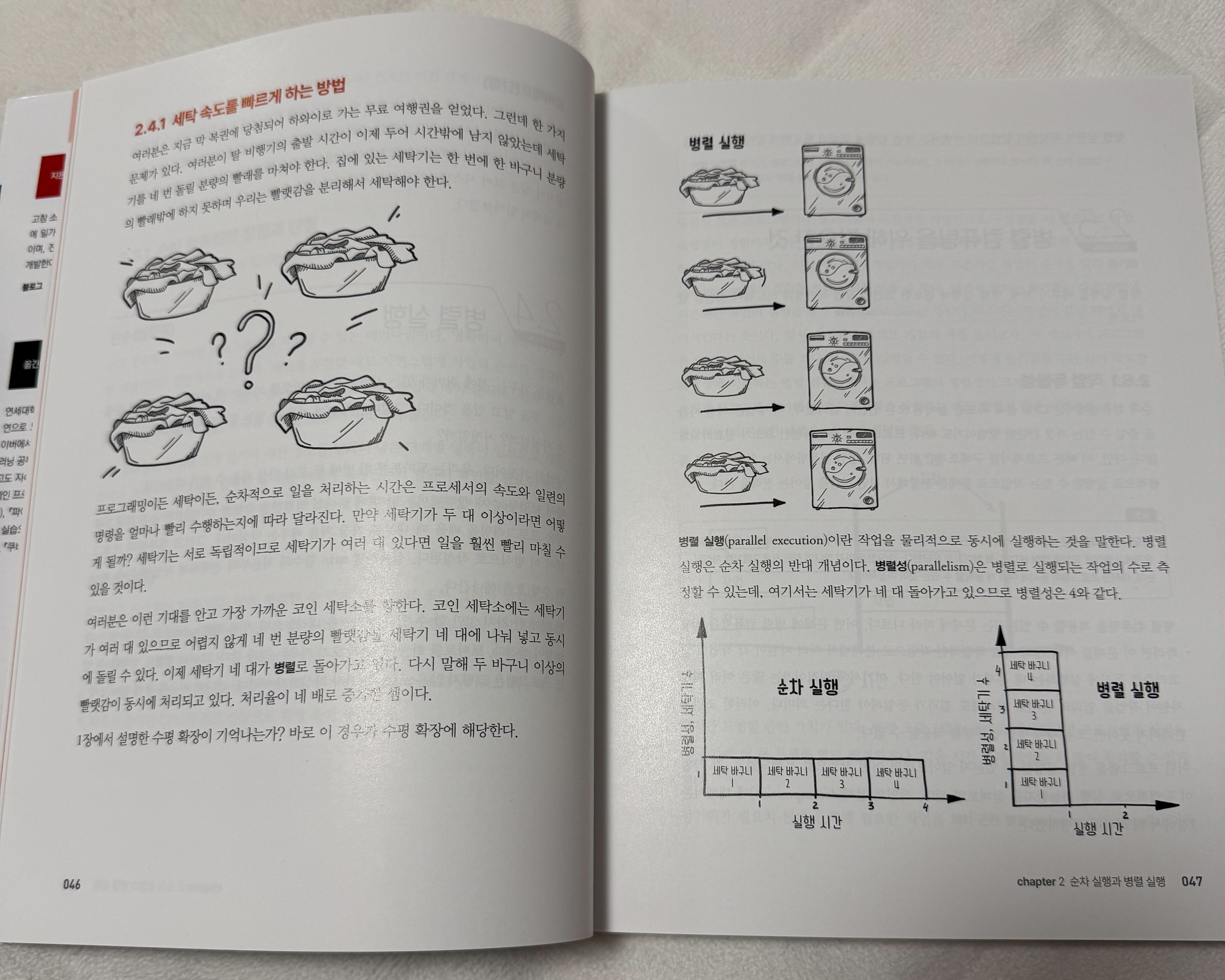
2.1. 동시성과 병렬성: 기본 개념의 명확화
동시성과 병렬성은 비슷해 보이지만 근본적으로 다른 개념이다. 이 책에서는 암달의 법칙(Amdahl’s Law)과 구스타프슨의 법칙(Gustafson’s Law)을 이용해 이를 설명하며 데이터 엔지니어링에서도 이러한 차이를 이해하는 것이 중요하다.

- 동시성(Concurrency): 여러 작업을 동시에 진행하는 것처럼 보이지만 실제로는 한정된 리소스를 공유하며 실행된다. 예를 들어, Python의
asyncio를 활용한 데이터 크롤링이 이에 해당한다. - 병렬성(Parallelism): 여러 코어에서 여러 작업을 물리적으로 동시에 실행된다. 예를 들어, Spark에서 RDD(Resilient Distributed Dataset)를 여러 노드에서 동시에 처리하는 것이 병렬성의 예다.
두 개념을 명확히 이해하면 데이터 엔지니어링에서 특정 작업을 수행할 때 적절한 모델을 선택할 수 있다.
2.2. 프로세스와 스레드: 적절한 사용법
데이터 파이프라인을 설계할 때는 프로세스와 스레드의 차이를 이해하는 것이 중요하다. 책에서는 이를 다음과 같이 정리하고 있다.
- 프로세스 기반 처리: 독립적인 메모리 공간을 사용하며 서로 영향을 미치지 않는다. 예를 들어, Apache Spark는 다중 프로세스를 활용하여 대규모 데이터를 병렬로 처리한다.
- 스레드 기반 처리: 공유 메모리를 사용하여 보다 가볍게 실행되지만 동기화 문제(예: 데드락, 경쟁 조건)가 발생할 가능성이 크다. Python의
ThreadPoolExecutor를 이용한 데이터 크롤링이 이에 해당한다.
데이터 엔지니어링에서는 다음과 같이 활용할 수 있다.
- ETL 파이프라인: 대규모 데이터를 로드할 때는 프로세스 기반 접근이 적합함 (Spark, Hadoop)
- 실시간 스트리밍 데이터 처리: Kafka 또는 Flink를 사용하여 스레드 기반 접근이 유리함
2.3. 비동기 I/O와 이벤트 기반 처리

I/O가 많은 데이터 처리(예: API 크롤링, 데이터베이스 조회, 파일 입출력)에서는 CPU보다는 I/O 성능이 병목이 된다. 책에서는 논블로킹 I/O와 이벤트 기반 처리를 설명하며, 데이터 엔지니어링에서 다음과 같은 활용 사례를 제시할 수 있다.
- Kafka Consumer 최적화: 메시지를 동기적으로 처리하면 성능이 저하되므로 비동기 I/O를 활용하여 여러 메시지를 동시에 가져와 처리하는 방식이 유리하다.
- Flink의 Async I/O: 외부 데이터 소스(MySQL, Redis 등)와 통합할 때 비동기 방식으로 데이터를 불러오면 처리 속도를 높일 수 있다.
- Python
asyncio를 이용한 웹 크롤링: 여러 웹 페이지를 동시에 요청하여 빠르게 데이터를 수집하는 데 사용된다.
2.4. 동기화와 경쟁 조건 해결
동시성을 활용할 때 가장 큰 문제 중 하나는 경쟁 조건(Race Condition)과 데드락(Deadlock)이다.

- 경쟁 조건 해결: 뮤텍스(Mutex), 세마포어(Semaphore) 등을 이용해 공유 자원을 보호해야 한다.
- 데드락 해결: 교착 상태를 방지하기 위해 트랜잭션 순서를 미리 정의하는 방식이 필요하다.
데이터 엔지니어링에서는 데이터 레이크 및 데이터 웨어하우스에서 동시에 다중 트랜잭션을 처리할 때 이러한 문제가 발생할 수 있으며 이를 방지하기 위해 동기화 기법을 적용해야 한다.
3. 데이터 엔지니어링에서의 활용법
3.1. 멀티프로세싱과 멀티스레딩을 활용한 대규모 데이터 처리
데이터 엔지니어링에서는 대량 데이터를 빠르게 처리하기 위해 병렬성을 적극 활용해야 한다.

- Spark와 Flink의 차이점 이해: Spark는 RDD 기반의 분산 처리이며 Flink는 스트림 기반으로 실시간 처리에 특화되어 있다.
- 멀티스레딩 기반 ETL 파이프라인: Pandas 또는 Dask를 활용해 멀티스레딩 기반의 데이터 파이프라인을 구축할 수 있다.
- Airflow의 태스크 병렬 실행: Airflow에서 동시성을 활용하여 여러 ETL 태스크를 병렬로 실행할 수 있다.
3.2. 데이터 스트리밍 시스템 최적화
Kafka, Flink, Spark Streaming 등을 활용하여 데이터 스트리밍 시스템을 구축할 때, 이 책에서 설명하는 비동기 I/O, 논블로킹 모델, 이벤트 기반 처리를 적용하면 성능을 대폭 향상시킬 수 있다.
3.3. 분산 컴퓨팅 환경에서의 동시성 적용
분산 시스템에서는 여러 노드에서 작업을 동시에 수행해야 한다. 이 책에서 다루는 동시성 개념을 활용하면 다음과 같은 환경에서 최적화할 수 있다.
- Hadoop MapReduce를 이용한 데이터 처리
- Kubernetes 기반의 동적 워크로드 관리
- Redis, Cassandra 등의 NoSQL DB에서 동시성 최적화
4. 데이터 엔지니어가 이 책을 읽어야 하는 이유
『그로킹 동시성』은 단순한 개념서가 아니라 실제로 적용 가능한 동시성 프로그래밍 기법을 직관적으로 설명하는 실용적인 가이드 같은 느낌이다. 데이터 엔지니어링에서 동시성과 병렬성을 이해하고 이를 적절하게 활용하면 성능과 확장성이 뛰어난 데이터 처리 시스템을 구축할 수 있다.
✅ 추천 대상
- 고성능 데이터 파이프라인을 설계하고 싶은 데이터 엔지니어
- 비동기 프로그래밍과 논블로킹 I/O를 활용하고 싶은 백엔드 개발자
- 실시간 데이터 스트리밍 시스템을 구축하려는 개발자
🔥 종합: 이 책은 데이터 엔지니어에게 필수적인 동시성 개념을 실용적으로 설명하며 Spark, Flink, Kafka 등의 동시성이 프로그래밍이 중요한 도구를 활용하는 데 있어서도 많은 인사이트를 제공한다. 데이터 처리 속도를 높이고 확장성이 뛰어난 시스템을 구축하고 싶다면 꼭 읽어야 할 책이다. 🚀
이 글은 길벗 출판사에서 책을 제공받아 작성된 글입니다.
Leave a comment